7天可退款
- 系统学习
- 24周
- 教学服务
- 10个月
- 教学模式
- 学练一体化
- 课程证书
- 通过得证书










课程大纲及学习周期安排
坚持学习的路上,我们为你画好成长路标
阶段一:走进大数据
- 第1周
- 第2周
在步入大数据殿堂之前,先带领大家快速掌握大数据的必备技能:Linux的操作使用,为后面学习大数据技术打下坚实基础。预习资料传送门:http://u3v.cn/5Moy2x
- 1、掌握Linux虚拟机的安装和配置
- 2、掌握Linux中常见高级命令(vi、wc、sort、date、jps、kill等命令)的使用 3、掌握Linux中三剑客(grep、sed、awk)的常见用法
- 4、掌握Linux的高级配置(ip、hostname、防火墙)
- 5、掌握Shell脚本的开发
- 6、掌握Linux中Crontab定时器的使用
- 【本周思考与讨论】
- 1、某云服务器被挖矿病毒程序侵入,病毒程序很顽强,如何开发一个脚本监控并杀掉此病毒程序?
- 2、利用学习的Linux高级技能实现论坛访问日志数据分析,看一下到底是谁在暴力攻击你的网站?
- 学习贵在坚持,每天进步一点点!
本周带领大家了解Hadoop,掌握HDFS、MapReduce、YARN的核心原理及实操内容,包括小文件和数据倾斜的问题及解决方案。
- 课程安排:
- 1、Hadoop的核心原理及架构
- 2、HDFS常见Shell命令的使用
- 3、MapReduce核心原理及实战
- 4、小文件问题之SequenceFile+MapFile
- 5、数据倾斜问题分析及解决方案
- 6、YARN的核心原理及架构分析
- 7、Hadoop在CDH和HDP中的使用
- 【本周思考与讨论】
- 1、如果让你规划一套大数据平台的部署方案,你会如何规划?
- 2、谈一下你对本地计算的理解?它的计算性能为什么这么高?
- 授人以鱼不如授人以渔,加油,打工人!
阶段二:PB级离线数据计算分析存储方案
- 第3周
- 第4周
- 第5周
Flume是一个分布式、高可靠、高可用的系统,能够有效的收集、聚合、移动大量的日志数据,在这里通过原理、实战、监控、优化等层面对Flume进行学习。
- 1、Flume核心原理及架构介绍
- 2、Flume的三大核心组件详解
- 3、案例:采集文件内容上传至HDFS
- 4、Flume高级组件之Source Interceptors、Channel Selectors和Sink Processors
- 5、Flume性能优化及进程监控
- 【本周思考与讨论】
- 1、设想一下,给你几百台机器让你采集日志数据,应该如何快速高效的实现?
- 2、如何开发一个通用的监控程序来监控Flume进程的运行情况,实现监控+预警+自动重启一条龙服务?
- 合适的才是最好的,技术选型的时候要坚持此原则!
掌握Hive的核心原理及架构,包括Hive SQL的深度使用。针对Hive中的数据压缩格式、数据存储格式、SQL执行计划进行扩展分析,进一步提高Hive的存储能力和计算性能。
- 1、Hive的核心原理及架构分析
- 2、Hive中数据库和表的操作
- 3、Hive表类型详解(内部表+外部表+分区表+桶表)
- 4、Hive高级函数详解(分组排序取TopN+行转列+列转行)
- 5、常见的数据压缩格式及存储格式(TextFile\ORC\Parquet)的原理及案例实战
- 6、Hive SQL常见性能优化
- 【本周思考与讨论】
- 1、针对小文件的问题,在Hive中应该如何解决?
- 2、在Hive数据仓库中应该如何选择合适的数据存储格式和压缩格式?
HBase是一个高可靠 、高性能 、面向列 、可伸缩的NoSQL数据库,解决了HDFS无法实现修改删除的问题,适合应用在高并发实时读写的应用场景中。
- 1、HBase核心原理及架构介绍
- 2、HBase常用命令实战(基础命令+DDL命令+DML命令)
- 3、HBase JavaAPI的核心功能使用
- 4、HBase内部核心组件详解(Region+WAL+HFile)
- 5、HBase中列族和Rowkey的高级设置
- 6、HBase批量导入和批量导出功能详解
- 7、HBase扩展内容(Hive+HBase、Phoenix、协处理器、Elasticsearch+HBase)
- 【本周思考与讨论】
- 1、想支持海量数据读写需求和SQL查询分析需求,有哪些解决方案或技术组件可以实现?
- 2、HDFS是不支持修改删除的,为什么HBase是基于HDFS的,HBase却可以支持修改删除?
阶段三:Spark+电商离线数据仓库设计与实战
- 第6周
- 第7周
- 第8周
- 第9周
Scala的函数式编程受到很多框架的青睐,例如Kafka、Spark等框架都是使用Scala作为底层源码开发语言,下面就带着大家7天极速掌握Scala语言。
- 1、快速了解Scala
- 2、Scala中基础功能的使用(变量、数据类型、表达式、循环)
- 3、Scala集合体系的使用(Set+List+Map)
- 4、Scala中函数的使用
- 5、Scala中的面向对象编程
- 6、Scala中的函数式编程
- 【本周思考与讨论】
- 1、谈一下你对Scala语言的认知,Scala和Java有什么异同?Scala的语法格式和Python有没有相似之处?
- 2、如何使用Scala实现单例设计模式?Scala中不支持静态关键字,如何实现单例?
结合实际案例详细分析Spark中的Transformation算子和Action算子使用。通过对Spark中的宽依赖、窄依赖、Stage、Shuffle机制进行详细分析,加深对Spark的理解。
- 1、Spark核心原理及架构详解
- 2、Spark Core 案例实战开发(Java+Scala)
- 3、Spark Transformation和Action算子开发实战
- 4、Spark中宽依赖和窄依赖核心原理介绍
- 5、Spark程序性能优化分析(Kryo、并行度、算子优化、数据本地化、JVM调优等)
- 6、Spark SQL快速上手使用
- 【本周思考与讨论】
- 1、谈一下你对宽依赖和窄依赖的理解,以及Stage的个数和宽依赖之间的关系?
- 2、谈一下你对Spark性能优化的总结,到底哪种优化策略的效果最明显?
基于Spark3.x版本进行更新迭代,重点分析Spark3.x中的特性,扩展SparkSQL相关内容,并且增加Spark Shuffle新方案-Celeborn。
- 1、Spark 3.X版本特性介绍
- 2、在已有的大数据集群中集成Spark 3.x环境
- 3、Spark 3.x之自适应查询执行原理及实战详解
- 4、Spark 3.x之动态分区裁剪原理及实战详解
- 5、SparkSQL 深度集成Hive实现元数据共享
- 6、Spark Shuffle新方案-Celeborn
- 【本周思考与讨论】
- 1、禁用动态优化倾斜的 Join策略时,如何解决数据倾斜问题?
- 2、动态分区裁剪和SQL中的谓词下推有什么关系?
整合各个业务线数据,为各个业务系统提供统一&规范的数据出口。通过对项目的由来,需求、技术进行分析和选型,实现用户行为数据数仓和商品订单数据开发数仓。
- 1、数据仓库项目需求分析及效果展示
- 2、用户行为数据+商品订单生成和采集
- 3、用户行为数据数仓分层开发(ODS+DWD+DWS+APP)
- 4、商品订单数据数仓分层开发
- 5、数据可视化之Zepplin的使用
- 6、数据仓库任务调度之Azkaban的使用
- 【本周思考与讨论】
- 1、使用Hive SQL可以实现数据清洗,使用Spark代码也能实现数据清洗,有什么区别吗?
- 2、谈一下你对数据仓库分层的理解,如果分成3层或者5层可以吗?
阶段四:高频实时数据处理+海量数据全文检索方案
- 第10周
- 第11周
- 第12周
- 第13周
- 第14周
- 第15周
- 第16周
- 第17周
Kafka是一个支持高吞吐、持久性、分布式的消息队列,非常适合海量数据的实时生产和消费,详细分析了Kafka的核心原理、代码实战、性能优化,以及Kafka的企业级应用。
- 1、Kafka核心原理及架构详解
- 2、Kafka中的生产者和消费者的使用
- 3、Kafka中的存储策略和容错机制
- 4、Java代码实现生产者和消费者
- 5、Kafka的三种语义详解
- 6、Kafka参数调忧(JVM参数调忧+Replication参数调忧+Log参数调忧)
- 7、实战:Flume深度集成Kafka
- 【本周思考与讨论】
- 1、如何开发一个基于Kafka的Topic Offset变化智能监控工具?
- 2、如何开发一个基于Kafka的消费者待消费数据(lag)监控告警工具?
Redis是一种面向键值对的NoSQL内存数据库,可以满足我们对海量数据的读写需求,在这里我们学习Redis中的五种常用数据类型以及Redis中的一些高级特性,达到快速上手使用。
- 1、Redis核心原理介绍
- 2、Redis常用数据类型详解(String+Hash+List+Set+Sorted Set)
- 3、Redis高级特性详解(expire+pipeline+info)
- 4、Redis持久化策略详解(RDB+AOF)
- 5、Redis的安全策略和监控命令-monitor
- 6、Redis架构演进过程详解
- 【本周思考与讨论】
- 1、如何使用Redis实现一个带有优先级的先进先出队列?
- 2、Redis的内存碎片问题如何解决?
快速了解Flink的基本原理和核心特点,掌握Flink中流数据和批数据的编程思路和代码实战,Flink中Standalone集群、ON YARN集群的安装部署,以及Flink中核心API的使用。
- 1、Flink核心原理及架构详解
- 2、Flink 实时计算程序开发
- 3、Flink DataStream API详解(DataSource+Transformation+DataSink) 4、Flink中Window和Time详解
- 5、Flink中并行度和核心原理及应用实战
- 6、Flink Application模式的核心原理及应用
- 【本周思考与讨论】
- 1、Flink中的哪些算子容易产生数据倾斜?
- 2、如何解决Flink中实时数据乱序的问题?
对Flink中的State(状态)的使用与管理进行深度扩展,包括State的快照生成和恢复,最后以Kafka+Flink+Kafka场景为例整体分析了Flink任务如何实现端到端的一致性!
- 1、Flink中State的核心原理深度剖析
- 2、Keyed State的核心原理及案例实战(ValueState、MapState、ListState) 3、Operator State的核心原理及案例实战(ListState、UnionListState、BroadcastState)
- 4、Flink中State的容错与一致性详解
- 5、Flink中Checkpoint和Savepoint的核心原理及案例实战
- 6、Kafka+Flink+Kafka实现端到端一致性(Exactly-once语义)
- 【本周思考与讨论】
- 1、如何基于Mysql实现一个支持Exactly-once语义的Sink组件?
- 2、在RocksDB中,针对key-value类型的数据,使用ValueState和MapState哪种数据类型效率高?
主要涉及Flink SQL中的常规流数据处理,以及FlinkSQL双流JOIN的用法,包括普通Join、时间区间Join、快照Join、维表Join、窗口Join等Join类型的原理及实战。
- 1、Flink SQL快速理解(离线计算+实时计算)
- 2、Flink SQL中静态表和动态表的原理及案例实战
- 3、Flink SQL Client客户端工具的使用
- 4、Hive SQL离线Join VS Flink SQL双流Join
- 5、Flink SQL双流JOIN案例实战(Regular Join、Interval Join、Temporal Join、Lookup Join、Window Join)
- 6、Flink SQL之Checkpoint和State TTL
- 【本周思考与讨论】
- 1、Flink SQL多流Join和双流Join有什么区别吗?
- 2、Flink SQL读写Kafka动态表是否可以实现仅一次语义?
- 3、Flink SQL开启Hive方言之后是否可以支持Hive中的函数?
- 4、Flink SQL中的哪些功能会借助于State实现?
Apache StreamPark是一个一站式的流处理计算平台,基于它开发流处理(Flink)任务, 可以极大降低学习成本和开发门槛。
- 1、目前实时计算(流处理)面临的问题
- 2、Apache StreamPark核心原理及架构
- 3、基于StreamPark提交Flink SQL任务
- 4、基于StreamPark提交Flink Jar包任务
- 5、基于StreamPark Rest API管理Flink任务
- 6、StreamPark在湖仓项目中的应用
- 【本周思考与讨论】
- 1、Apache StreamPark和Apache DolphinScheduler如何结合到一起使用?
- 2、谈一下你对Apache StreamPark在流式计算领域中所处角色的理解?
Kyuubi 是一个分布式、多租户、高性能的SQL网关,可以为众多计算引擎(Spark、Flink、Hive)提供SQL查询服务。
- 1、Kyuubi核心原理及架构
- 2、大数据SQL网关方案对比
- 3、Kyuubi集成Spark SQL引擎(默认)
- 4、Kyuubi集成Hive SQL引擎
- 5、Kyuubi集成Flink SQL引擎
- 6、Kyuubi Connectors案例实战
- 7、Kyuubi JDBC Driver案例实战
- 【本周思考与讨论】
- 1、在湖仓架构中引入Kyuubi有什么好处?
- 2、如果让你自己开发一个通用大数据分析平台,应该如何对Kyuubi进行封装?
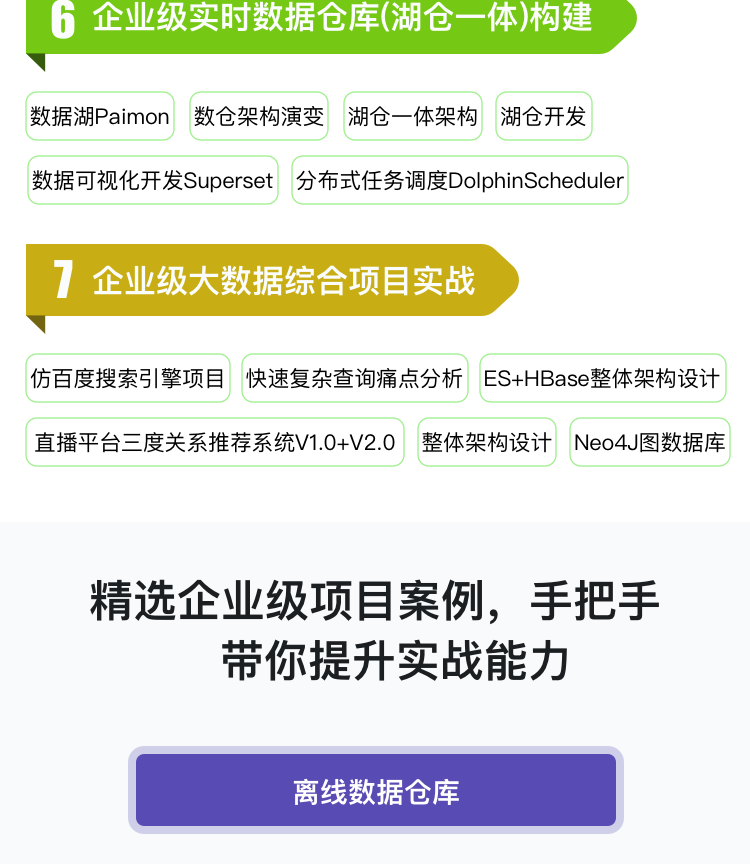
Elasticsearch是一个基于Lucene的分布式全文检索引擎,解决了海量数据下数据多条件快速复杂查询的痛点。基于Elasticsearch+HBase实现仿百度搜索引擎的海量数据存储和检索功能。
- 1、Elasticsearch核心原理及架构详解
- 2、ES中分词器的作用及案例实战(集成中文分词插件es-ik、添加自定义词库、热更新词库)
- 3、Elasticsearch Search查询功能详解(包括过滤、分页、排序、高亮、评分依据等)
- 4、Elasticsearch 性能优化策略分析
- 5、海量数据存储+快速复杂查询需求分析及解决方案
- 6、从0~1开发仿百度搜索引擎项目
- 【本周思考与讨论】
- 1、为什么要基于Elasticsearch+HBase实现海量数据存储和建立索引,单独使用Elasticsearch不行吗?
- 2、Hive、Impala、Spark、Flink这些引擎为什么不适合海量数据检索需求?
阶段五:综合项目:三度关系推荐系统
- 第18周
- 第19周
构建直播平台用户三度关系推荐系统,详细分析数据采集/数据分发/数据存储/数据计算/数据展现等功能,完整复现互联网企业大数据项目从0~1,从1~N的开发过程。
- 1、项目需求分析及整体架构设计
- 2、Neo4j快速上手使用
- 3、数据采集架构详细分析及设计
- 4、数据计算核心指标详细分析与实现
- 5、三度关系推荐流程开发
- 6、项目核心内容总结
- 【本周思考与讨论】
- 1、如果让你来设计这个项目的架构,你会如何设计?
- 2、如何使用Spark代码实现三度关系列表数据导出MySQL?
分析V1.0架构存在的问题及弊端,重新设计整体架构方案,进行迭代优化,基于最新的架构方案重新实现核心功能代码,开发数据接口,优化数据传输逻辑,提高数据安全性。
- 1、现有V1.0技术架构分析及V2.0技术架构设计
- 2、数据计算核心指标详细分析
- 3、数据计算核心模块开发
- 4、三度关系列表数据导出到Redis
- 5、数据接口定义与开发
- 6、项目核心内容总结
- 【本周思考与讨论】
- 1、如何使用Flink代码实现三度关系列表数据导出到Redis?
- 2、针对目前Neo4j中的数据,还有哪些属性需要建立索引?
阶段六:电商实时数据仓库(湖仓一体)设计与实战
- 第20周
- 第21周
- 第22周
- 第23周
- 第24周
详细分析了目前业内常见的OLAP数据分析引擎,重点学习ClickHouse的核心原理及使用,包括常见的数据类型、数据库、MergeTree系列表引擎、分布式集群、副本、分片、分区等核心功能的使用。
- 1、OLAP引擎的起源和分析
- 2、ClickHouse的核心原理及架构分析
- 3、ClickHouse中常见数据类型的使用(基础、复合、特殊数据类型)
- 4、ClickHouse中数据库和表的使用
- 5、MergeTree(合并树)系列表引擎原理分析及实战
- 6、ClickHouse完整查询语句的使用(包括WITH、IN、JOIN)
- 【本周思考与讨论】
- 1、HBase是否可以替代ClickHouse?
- 2、ClickHouse在实时数据仓库中的定位?
针对实时数据仓库项目中需要用到的数据监控(Kafka Eagle)和任务调度(DolphinScheduler)技术组件进行扩展,为构建实时数据仓库提供底层技术支撑。
- 1、Kafka Eagle(EFAK)核心原理分析
- 2、Kafka Eagle(EFAK)常见功能的使用
- 3、DolphinScheduler核心原理及架构分析
- 4、DolphinScheduler常见功能介绍
- 5、DolphinScheduler案例实战(Shell任务、HiveSQL任务、Spark任务、Flink任务、Flink SQL任务)
- 【本周思考与讨论】
- 1、如果需要自研一个Kafka监控平台,你希望如何设计?
- 2、谈一下你的主流分布式任务调度工具的理解
针对实时数据仓库项目中需要用到的数据库实时数据采集(Flink CDC)技术组件进行扩展,为构建实时数据仓库提供底层技术支撑。
- 1、Flink CDC 核心原理及架构介绍
- 2、Flink CDC之MySQL CDC快速上手使用
- 3、MySQL CDC之基于DataStream API实现数据采集和处理
- 4、MySQL CDC之基于Flink SQL实现数据采集和处理
- 5、MySQL CDC支持的高级特性(数据读取策略、全增量一体化、增量快照数据读取算法、Exactly-Once 语义、动态加表、分库分表、元数据列)
- 6、MySQL CDC使用中可能遇到的问题
- 【本周思考与讨论】
- 1、Flink CDC 如何采集数据库中没有主键的表?
- 2、Flink CDC是否可以取代Sqoop这种采集工具?
涉及Paimon中的核心原理及架构,Flink SQL和Paimon的实战案例,Paimon CDC数据摄取功能,以及Paimon中快照、分区、小文件的管理,为构建湖仓一体架构提供底层技术支撑。
- 1、Apache Paimon的核心原理及架构介绍
- 2、Paimon中表的使用(内部表\外部表\分区表\临时表\主键表\仅追加表)
- 3、Paimon中Changelog Producers和Merge Engines的原理及案例实战
- 4、Paimon底层存储文件深入剖析
- 5、Paimon CDC数据摄取功能详解
- 6、Paimon中快照、分区、小文件、标签、Bucket的管理和使用
- 【本周思考与讨论】
- 1、Paimon与计算引擎(Flink\Spark\Hive)之间的关系?
- 2、Paimon能否取代Kafka实现消息队列的功能?
基于Flink SQL+Paimon+Hive构建湖仓一体项目,提高数据分析时效性,为业务部门提供分钟级别的实时数据支撑。
- 1、离线数据仓库架构分析
- 2、实时数据仓库架构分析(Lambda+Kappa+湖仓一体)
- 3、项目核心技术组件选型
- 4、实时数仓整体架构设计(湖仓一体架构)
- 5、用户行为数据湖仓+商品订单数据湖仓开发
- 6、数据大屏制作(Superset)+湖仓项目任务调度
- 【本周思考与讨论】
- 1、针对目前的架构,谈一下你的理解,还可以做哪些调整?
- 2、谈一下你湖仓一体架构的理解和认识?


评价 好评
-

qq_森林中的小熊_0
 好评
好评
课程讲解由浅入深,能做到详细解答的同时又让人容易理解,工作中会遇到的以及面试常问的问题都有涵盖,感谢徐老师。
-

Crazy酱汁
好评
非常棒非常棒,老师讲解细致,有专属学习群,氛围浓郁,遇到问题还帮忙解答,遇到技术难关给建议,面试帮忙看简历给建议,真是物超所值!新手小白提升转岗均适宜!
-

codesci
好评
棒棒棒!每次打开课程心情都是振奋的(这个课怎么这么好的激动心情)。高质量的课程搭配了完善到令人发指的资料笔记;学习课程给人的感觉,就像躺在床上,有人把饭喂到嘴里的,然后说,真香。 期待能成功从JAVA开发转型成为大数据开发工程师!




预售规则
1. 定金支付成功后,可在“我的订单”-“未支付”栏查看所要支付尾款的订单。
2. 尾款支付开启后,请在规定时间内支付尾款,若超出尾款支付时间,订单将自动关闭。请关注短信、慕课网平台及慕课网微信号等渠道推送的提醒消息。
3. 定金可在课程原价基础上抵扣页面显示金额,具体数额及计算方式见详情页。
4. 已支付定金但未在规定时间支付尾款的用户,定金不可退。
5. 如您对预售活动有其它疑问,请联系客服:kf@imooc.com。